基本概念
influxdb v.s. mysql
| influxdb | mysql |
|---|---|
| database | 数据库 |
| measurement | 表,但不支持联合查询 |
| points | 行 |
| timestamp | 主键 |
| tag | 有索引的列 |
| field | 没索引的列 |
| continuous queries 持续查询 | 存储过程 |
| retention policy 存储策略 | 存储过程 |
| subscription 订阅 | 存储过程 |
配置
数据文件配置
将占用空间的数据文件转换磁盘空间大的地方
1
2
3
4
mkdir /home/work/influxdb
chown -R influxdb:influxdb /home/work/influxdb
编辑配置文件
1
vim /etc/influxdb/influxdb.conf
1
2
3
4
5
[meta]
dir = "/home/work/influxdb/meta"
[data]
dir = "/home/work/influxdb/data"
wal-dir = "/home/work/influxdb/wal"
端口配置
编辑配置文件
1
vim /etc/influxdb/influxdb.conf
1
2
3
4
5
6
# Bind address to use for the RPC service for backup and restore. 备份与恢复端口
bind-address = "127.0.0.1:8088"
[http]
auth-enabled = false
# The bind address used by the HTTP service HTTP API接口
bind-address = ":8086"
修改默认端口是好的安全习惯
日志配置
日志文件存储
1
vim /etc/init.d/influxdb
1
2
3
if [ -z "$STDERR" ]; then
STDERR=/home/work/influxdb/log/influxd.log
fi
HTTP日志分离
编辑配置文件
1
vim /etc/influxdb/influxdb.conf
1
2
[http]
access-log-path = "/home/work/influxdb/log/http.log"
日志切割
- influxdb 系统日志
1
vim /etc/logrotate.d/influxdb
1 2 3 4 5 6 7 8
/home/work/influxdb/log/influxd.log { daily rotate 7 missingok dateext copytruncate compress }测试是否成功
1
logrotate -d /etc/logrotate.d/influxdb
- influxdb http日志
1
cp /etc/logrotate.d/influxdb /etc/logrotate.d/influxdb-http
1
vim /etc/logrotate.d/influxdb-http
1 2 3 4 5 6 7 8
/home/work/influxdb/log/http.log { daily rotate 7 missingok dateext copytruncate compress }测试是否成功
1
logrotate -d /etc/logrotate.d/influxdb-http
其他性能相关
` cache-max-memory-size = “2g” `
更多官方配置文档
启动
mac
` influxd -config /usr/local/etc/influxdb.conf 2>/usr/local/var/log/influxdb.log & `
centos
` sudo service influxdb start `
更多官方安装文档
管理
开启HTTP认证
- 更改配置文件,关闭HTTP认证 ` auth-enabled = false`
- 重启influxdb
sudo service influxdb restart - 创建管理员账号
1 2
CREATE USER admin WITH PASSWORD 'xxx' GRANT ALL PRIVILEGES TO admin
- 创建数据库读写账号
1 2 3 4 5 6 7 8 9
create database db_xxx create user db_xxx_reader with password 'xxx' create user db_xxx_write with password 'xxx’ grant read on db_xxx to db_xxx_read grant write on db_xxx to db_xxx_write - 更改配置文件,开启HTTP认证 ` auth-enabled = true`
- 重启influxdb
sudo service influxdb restart
备份与恢复
数据导入导出
- 导入
1
curl https://s3.amazonaws.com/noaa.water-database/NOAA_data.txt -o NOAA_data.txt
1
influx -host 127.0.0.1 -port 8086 -username admin -password test -import -path NOAA_data.txt -precision s -pps 5000
导入数据文件需遵循以下格式
1 2 3 4 5 6 7 8 9 10 11
# DDL CREATE DATABASE NOAA_water_database # DML # CONTEXT-DATABASE: NOAA_water_database h2o_feet,location=coyote_creek water_level=8.120,level\ description="between 6 and 9 feet" 1439856000 h2o_feet,location=coyote_creek water_level=8.005,level\ description="between 6 and 9 feet" 1439856360
更多 influx官方文档
- 导出
1
influx_inspect export -database NOAA_water_database -retention autogen -waldir ~/.influxdb/wal -datadir ~/.influxdb/data/ -out noaa_water_database.txt
身份认证与授权管理
安全
开启HTTPS
端口管理
身份认证与授权管理
监控
show stats
show diagnostics
_internal 数据库
需开启monitor监控配置项,默认开启
1
2
3
4
5
6
7
8
9
[monitor]
# Whether to record statistics internally.
# store-enabled = true
# The destination database for recorded statistics
# store-database = "_internal"
# The interval at which to record statistics
# store-interval = “10s"
示例:每秒写入的数据点数
1
http://127.0.0.1:8086/query?chunked=true&db=_internal&q=select+derivative%28pointReq%2C+1s%29+from+%22write%22+where+time+%3E+now%28%29+-+5m+tz%28%27Asia%2FShanghai%27%29
更多 _internal
数据保留策略 retention policies
- 查看数据保留策略
show retention policies on db_xxx
- 创建数据保留策略
create retention policy "rentionpolicy_xxx" on "db_xxx" duration 4w replication 1 default
- 删除数据保留策略
drop retention policy “rentionpolicy_xxx" on db_xxx
数据订阅 subscription
原理 : 将influxdb中的数据以line protocol格式通过HTTP/HTTPS/UDP发送出去
- 查看订阅
show subscriptions
- 创建订阅
create subscription "db_sub_xx" ON "db_xxx"."rentionpolicy_xxx" destinations all 'http://user:passwd@host:port'
- 删除订阅
drop subscription "db_sub_xx" on "db_xxx"."rentionpolicy_xxx"
订阅密码千万不要包含特殊字符
更多 数据订阅官方文档
存储数据
line protocol
数据类型
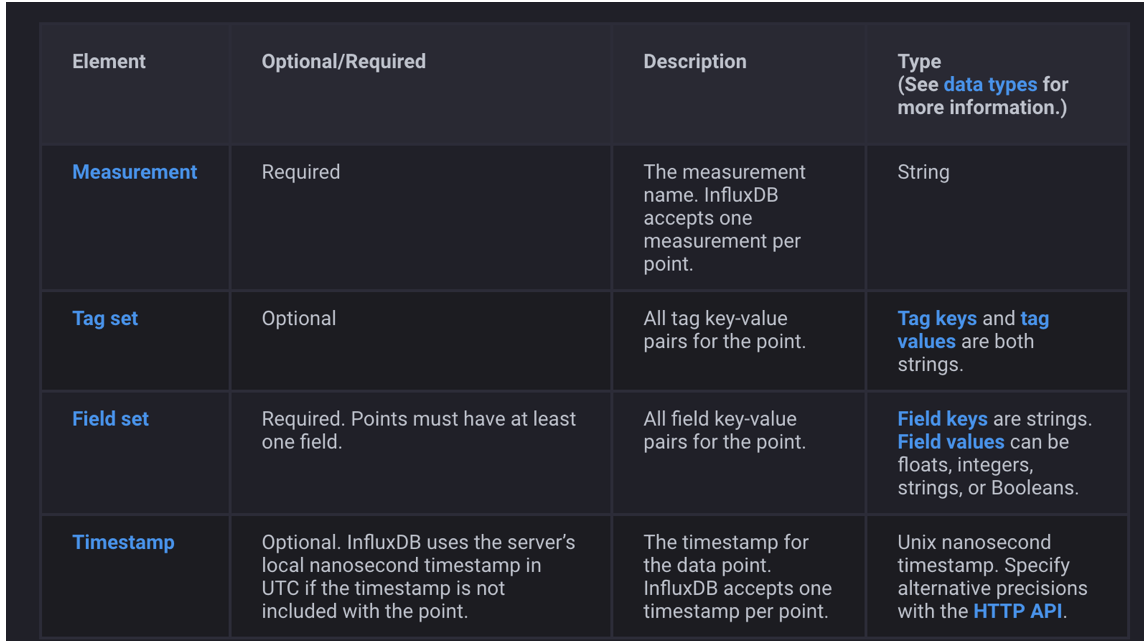
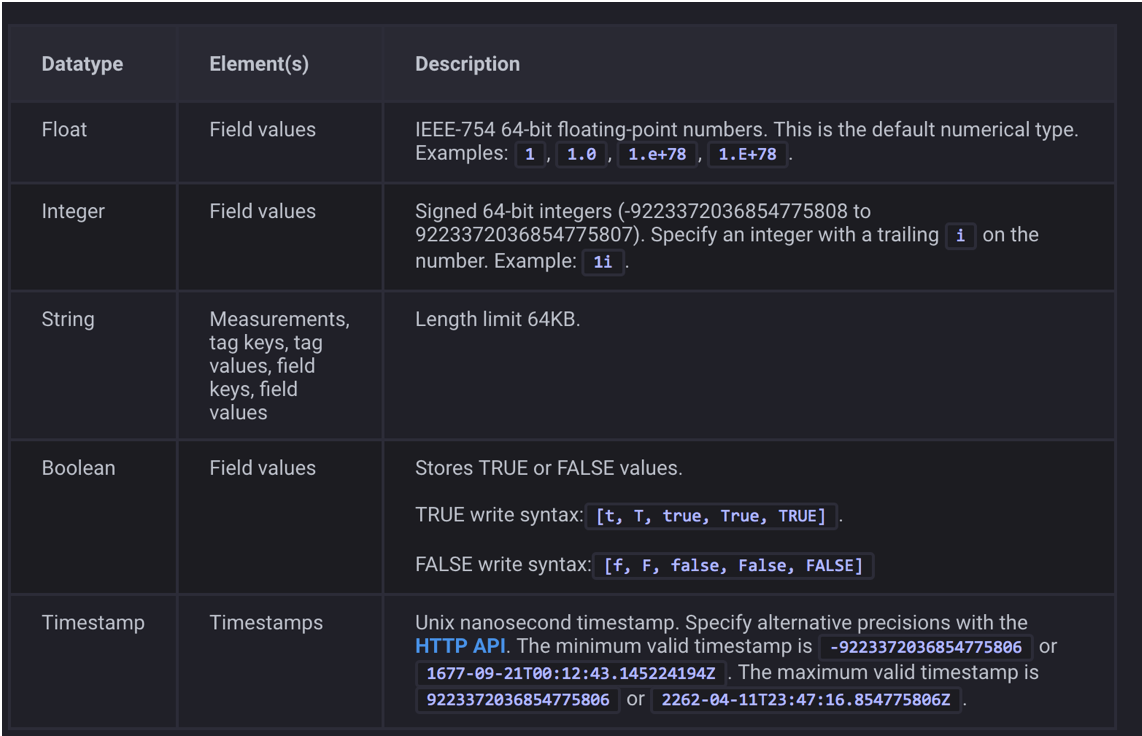
浮点数 float
整型 integer
字符串 string
布尔型 boolean
时间戳 timestamp
| 单位 | |
|---|---|
| ns | 纳秒 |
| u or µ | 微秒 |
| ms | 毫秒 |
| s | 秒 |
| m | 分钟 |
| h | 小时 |
| d | 天 |
| w | 周 |
管理数据
更多 查询语言规范官方文档
数据查询
查询 【重】
更多数据操作官方文档
select
select
- 至少要选定一个field
into
into
- 如果当前select 包含tag,会转化成另一张measurement的field,会损失数据
条件
where
- 按fields,tags,timestamps进行过滤
- timestamp格式支持
| rfc3339 | ‘YYYY-MM-DD HH:MM:SS.nnnnnnnnn’ |
| 时间戳 | 1439856000s |
| 相对 | time() - 7d |
分组
group by
- 按tags,timestamps进行分组
-
缺失值填充
fill(linear) fill(previous) fill(null)
排序
order by
- 只支持按time排序
限制
limit slimit
- limit,每个series返回的data point 数量
- slimit,返回的series数量
偏移量
offset soffset
时区选择
tz('Asia/Shanghai')
子查询
SELECT MEAN("difference") FROM (SELECT "cats" - "dogs" AS "difference" FROM "pet_daycare")
多语句
SELECT MEAN("water_level") FROM "h2o_feet"; SELECT "water_level" FROM "h2o_feet" LIMIT 2
操作符
+- ` -`
*/%&|^andor=<=>=<>!=<>=~!~//正则
更多 算术操作
强制转换
只支持数值型变量之间的强制转换
SELECT "water_level"::integer FROM "h2o_feet" LIMIT 4
持续查询
查看
show continuous queries
创建
create coninous query
删除
drop continous query
查询管理
sql运行详解
explain sql
explain analyze sql
查看当前运行的查询
show queries
杀掉指定查询
kill query
查询相关配置
| 配置项 | 默认值 | 说明 |
|---|---|---|
| max-concurrent-queries | 0 | 并发查询数 |
| query-timeout | 0 | 查询超时设置 |
| log-queries-after | 0 | 慢查询记录 |
| max-select-point | 0 | 数据点数量限制 |
| max-select-series | 0 | 序列数量限制 |
| max-select-buckets | 0 | 时间分桶限制 |
schema操作
数据库查看
show databases
measurement查看
show measurements
序列查看
show series
存储策略查看
show retention policies
标签key查看
show tag keys
标签取值查看
show tag values
字段key查看
show field keys
更多 schema操作
数据库操作
新建数据库
create database
删除数据库
drop database
删除序列
drop series
删除度量
drop measurement
删除分片
drop shard
删除数据点
delete
存储策略
创建
create retention policy
修改
alter retention policy
删除
drop retention policy
更多数据库操作
身份认证与授权管理
用户查看
show users
新建用户
create user "user_xx" with passsword "test"
权限授予
grant read on "db_xx" to "user_xx"
权限回收
revoke read on "db_xx" from "user_xx"
权限查看
show grants for user
删除用户
drop user "test"
更多 身份认证与授权管理
基数统计
度量的基数
show measurement cardinality
序列的基数
show sereis cardinality
标签key的基数
show tag key cardinality
标签value的基数
show tag values cardinality
字段key的基数
show field key cardinality
API
更多 api官方文档
性能报告
/debug/pprof
不需认证
http读写数据点统计
/debug/requests
不需认证
| 参数 | 可选/必须 | 说明 |
|---|---|---|
| seconds= | 可选 | 默认10s |
变量
/debug/vars
不需认证
存活探测
/ping
不需认证
响应码
| 响应码 | 说明 |
|---|---|
| 204 | 成功 |
curl -I http://localhost:8086/ping
查询
/query
数据库、存储策略、用户管理
| 请求方法 | 查询类型 |
|---|---|
| GET | select/show |
| POST | create/drop/alter/delete/grant/revoke/kill |
select into 需要用POST
参数
| 参数 | 可选/必须 | 说明 |
|---|---|---|
| chunked | 可选 | ture表示每次返回10000个数据点 |
| db | 必须 | 数据库 |
| q | 必须 | sql |
| epoch | 可选 | |
| u | 可选 | 用户名 |
| p | 可选 | 密码 |
| pretty | 可选 | 是否展开的json展示结果 |
当chunked设置为false时,返回结果不做切割处理,最大返回数据点数由max-row-limit配置项来配置
响应码
| 响应码 | 说明 |
|---|---|
| 200 | 成功 |
| 400 | 错误的sql语句 |
| 401 | 需要认证 |
写
/write
将数据插入到数据库
参数
| 参数 | 可选/必须 | 说明 |
|---|---|---|
| chunked | 可选 | ture表示每次返回10000个数据点 |
| db | 必须 | 数据库 |
| consistency | 可选 | 开源版不支持 |
| precision | 可选 | 精度 ns/u/ms/s/m/h |
| rp | 可选 | 存储策略名 |
| u | 可选 | 用户名 |
| p | 可选 | 密码 |
响应码
| 响应码 | 说明 |
|---|---|
| 200 | 成功 |
| 400 | 错误的sql语句 |
| 401 | 需要认证 |
| 404 | 数据库不存在 |
| 500 | 指定的存储策略不存在 |
最佳实践
注意:时序数据适合写多读少的场景
部署
- 数据文件分离
- 日志文件切割
- 开启认证
- 修改默认端口
- 根据数据量创建合适的存储策略与分片策略
influxdb每一个分片shard存储一个指定时间段内的数据。每一个分片都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm 文件 长分片:减少数据重复,提高压缩率,提高快速查询 短分片:删除数据更有效
| 存储策略 | 分片间隔 |
|---|---|
| <= 1 days | 6 hours |
| >1 day and <= 7 days | 1 day |
| >7 days and <= 3 months | 7 days |
| >3 months | 30 days |
| infinite | 52 weeks |
- 自建集群采取读写分离
- 写库:部署一台,负责数据录入与订阅数据到其他数据库
- 读库:部署N台,采用负载均衡lvs/nginx均衡查询请求
数据设计
- 在避开keyword的情况下不使用特殊字符命名标识符(数据库名,存储策略,用户名,度量名,标签名,字段名)
- 避免过多的series,tag的取值不要太多
- tag选用
- 不随时间变化
- 需要分组操作
- field选用
- 随时间会发生变化
- 需要使用函数计算
数据查询
- 查询时标识符使用双引号避免转义
- 查询时time的rfc3339格式使用单引号,并且需指定时区
- 中国时区只支持
- tz(‘Asia/Shanghai’)
- tz(‘Asia/Chongqing’)
- 查询时tag的取值使用单引号,因为tag的取值都是字符串类型
- 使用偏移量来控制group by time的起始位置
- 指定time条件时,不要用or
- 一次查询不要取太多的数据点
数据写入
- 插入数据时若field的类型为string,请使用双引号,特殊字符需要转义
- 数据写入时,注意覆盖情况 database+retentation policy+measurement+tag+ts确定唯一值,单重复时会自动合并field
数据删除
- drop操作耗性能,请谨慎使用
常见bug
tag取值个数超过10w
partial write: max-values-per-tag limit exceeded (100000/100000) 解决: 修改配置
max-values-per-tag = 0
cache内存使用超过1g
Execute error[code:500][err:{“error”:”engine: cache-max-memory-size exceeded: (1073741900/1073741824)”} 解决: 修改配置 ` cache-max-memory-size = “2g” `