聚合
个数
count()
注意:fill()函数会干扰count的统计
去重
distinct()
注意: select distinct into 会只有最后一条数据被保留下来
积分
integral()
数学含义:曲边三角形的面积
求和
sum()
算术平均
mean()
统计含义: 集中趋势的度量,对极端值非常敏感,如果数据中有异常点或者分布是有偏的,均值可能存在误导
中位数
median()
数学含义:位于中间位置的值
统计含义: 集中趋势的度量,对极端值不敏感
众数
mode()
数学含义:出现次数最多的值
统计含义: 集中趋势的度量
极差
spread()
数学含义:最大值与最小值的差
统计含义: 离散趋势的度量
标准差
stddev()
统计含义: 离散趋势的度量
备注: 离散度分析有以下几种方法
| 分析方法 | 适用类型 | 计算方式 | 说明 |
|---|---|---|---|
| 异众比例 | 分类型数据 | 非众数的频数与总频数的比值 | 值越小,说明众数的代表性越好 |
| 四分位差 | 顺序型数据/数值型数据 | 上四分位数和下四分位数之差 | 值越小,说明中间的50%的数据越集中 |
| 标准差 | 数值型数据 | 方差(均值的偏差平方和)的算术平方根 | 值越小,数据分散度越低 |
| 离散系数/变异系数 | 数值型数据 | 标准差与均值的比值 | 值越小,数据分散度越低 |
选择
最大/最小/百分位
max()
min()
percentile()
注意:
percentile(
percentile(
percentile(
TOP N/Bottom N
top()
bottom()
最旧/最新
first()
last()
采样
sample()
infuxdb 采用的Reservoir Sampling
转换
三角函数
acose()
asin()
atan()
atan2()
cos()
sin()
tan()
取整
ceil()
floor()
round()
对数
ln()
log()
log2()
log10()
指数
exp()
数学含义:以e为底数的指数函数
e^{x}
取幂
pow()
算术平方根
sqrt()
绝对值
abs()
持续时间
elapsed()
累积和 CUSUM (重)
cumulative_sum()
差值
difference()
non_negative_difference()
相邻数值的差值
导数(重)
derivative()
non_negative_derivative()
数学含义:数据的变化率
1
2
(2.116 - 2.064) / (360s / 1s)
应用场景: 服务器接收数据的速度来判定服务器的性能
移动平均 MA(重)
moving_average()
技术分析
相对强弱指标 RSI
relative_strength_index()
应用场景:金融
RS = \frac {SMMA(U,n)} {SMMA(D,n)}
RSI = 100 - \frac {100} {1 + RS}
SMMA(U,n) N天内收盘价上涨数之和的平均值
SUMA(D,n) N天内收市价下跌数之和的平均值
SUMA(smoothed or modified moving average)可以用EMA(exponential moving average) 替代
参考
钱德动量摆动指标 CMO
chande_momentum_oscillator()
应用场景:金融
\frac {S_u -S_d} {S_u + S_d} \times 100
Su是今天收盘价与昨日(上涨日)收盘价之差的加总;
Sd是今日收盘价与昨日(下跌日)收盘价之差的绝对值的加总。
上涨日被定义为当日收盘价高于前一日收盘价的那些日子。
下跌日被定义为当日收盘价低于前一日收盘价的那些日子。
参考: 钱德动量摆动指标
卡夫曼效率系数 ER
kaufmans_efficiency_ratio()
应用场景:金融
指数移动平均 EMA
exponential_moving_average()
双指数移动平均 DEMA
double_exponential_moving_average()
三指数移动平均 TEMA
triple_exponential_moving_average()
卡夫曼自适应移动平均 AMA
kaufmans_adaptive_moving_average()
三指数导数 TED
triple_exponential_derivative()
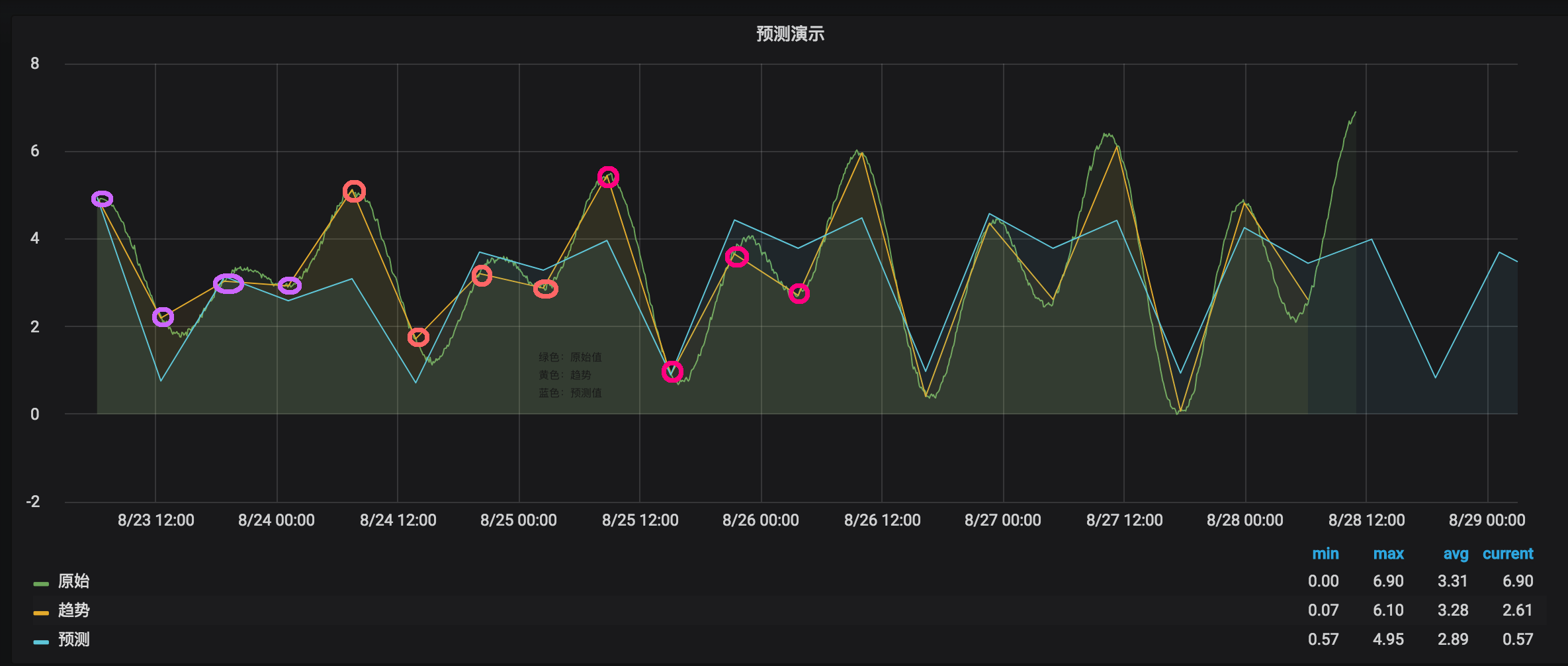
预测
Holt季节预测
holt_winter()
示例
SELECT "water_level" FROM "NOAA_water_database"."autogen"."h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-08-22 22:12:00' AND time <= '2015-08-28 03:00:00’
SELECT FIRST("water_level") FROM "NOAA_water_database"."autogen"."h2o_feet" WHERE "location"='santa_monica' and time >= '2015-08-22 22:12:00' and time <= '2015-08-28 03:00:00' GROUP BY time(379m,348m)
SELECT HOLT_WINTERS_WITH_FIT(FIRST("water_level"),10,4) FROM "NOAA_water_database"."autogen"."h2o_feet" WHERE "location"='santa_monica' AND time >= '2015-08-22 22:12:00' AND time <= '2015-08-28 03:00:00' GROUP BY time(379m,348m)
原始值每6分钟一个值
N: e.x. group by time(379m) N=10 收到10个预测值,每个预测值间隔379分钟
S: e.x. group by time(379m) S=4 每4个数据点一个季节模式
关键是知道数据的周期