基本概念
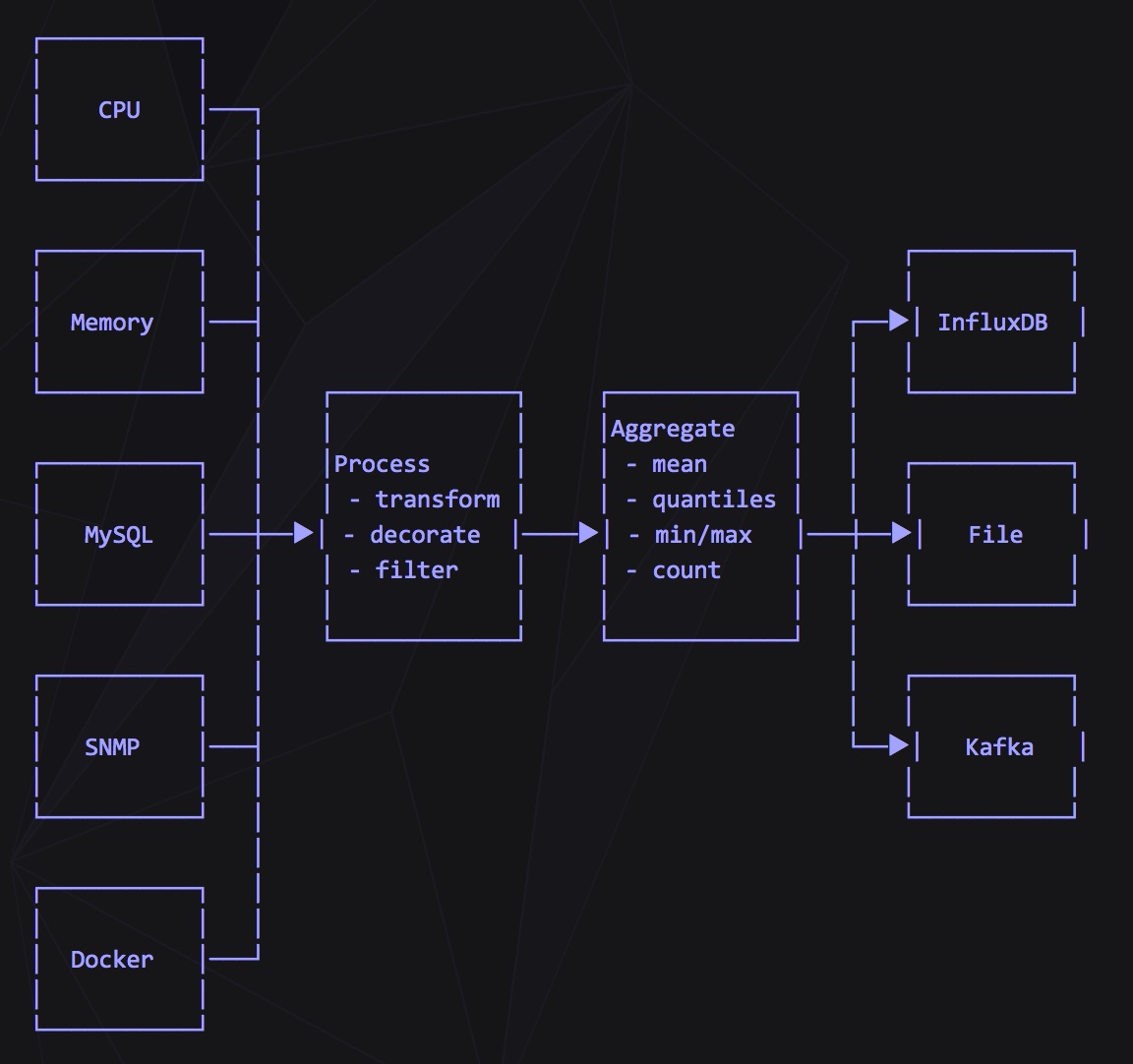
数据管道,输入输出端协商好格式,然后进行数据采集input、数据清理process、数据聚合aggregator、数据转发output,与logstash类似,但更强大,有非常多的插件
部署
安装
mac
1
2
brew update
brew install telegraf
配置文件
/usr/local/etc/telegraf.conf
centos
1
2
wget https://dl.influxdata.com/telegraf/releases/telegraf-1.8.3-1.x86_64.rpm
sudo yum localinstall telegraf-1.8.3-1.x86_64.rpm
配置文件
/etc/telegraf/telegraf.conf
配置
配置详解
配置由以下几个部分组成
全局tag
1
2
3
4
5
[global_tags]
# dc = "us-east-1" # will tag all metrics with dc=us-east-1
# rack = "1a"
## Environment variables can be used as tags, and throughout the config file
# user = "$USER"
代理
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
[agent]
## 数据收集周期
interval = "10s"
## 如果 interval="10s" :00, :10, :20 依次进行收集
round_interval = true
## 输出大小
metric_batch_size = 1000
## 缓存大小
metric_buffer_limit = 10000
## 接收插件休眠周期
collection_jitter = "0s"
## 数据flush周期
flush_interval = "10s"
## 发送插件休眠周期
flush_jitter = "0s"
## 支持的时间单位 "ns", "us" (or "µs"), "ms", "s".
precision = ""
## 调试模式
debug = false
## 静默模式
quiet = false
## 日志路径
logfile = ""
## 主机名,默认 os.Hostname()
hostname = ""
## 如果设置为true,tag中将没有host信息
omit_hostname = false
输出插件 (非常多)
以influxdb插件为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
[[outputs.influxdb]]
# urls = ["unix:///var/run/influxdb.sock"]
# urls = ["udp://127.0.0.1:8089"]
# urls = ["http://127.0.0.1:8086"]
## 输出数据库
# database = "telegraf"
## 输出时是否创建数据库,当telegraf没有权限创建数据库时设置为false
# skip_database_creation = false
## 存储策略,默认default策略
# retention_policy = ""
## Write consistency (clusters only), can be: "any", "one", "quorum", "all".
## Only takes effect when using HTTP.
#
# write_consistency = "any"
## http 超时设置
# timeout = "5s"
## HTTP 基本认证
# username = "telegraf"
# password = "metricsmetricsmetricsmetrics"
## HTTP User-Agent
# user_agent = "telegraf"
## UDP payload 大小限制
# udp_payload = 512
## https证书
# tls_ca = "/etc/telegraf/ca.pem"
# tls_cert = "/etc/telegraf/cert.pem"
# tls_key = "/etc/telegraf/key.pem"
## 是否跳过证书校验
# insecure_skip_verify = false
## http代理设置
# http_proxy = "http://corporate.proxy:3128"
## 自定义HTTP头
# http_headers = {"X-Special-Header" = "Special-Value"}
# HTTP Content-Encoding 编码, gzip或者identity
# content_encoding = "identity"
## 是否支持无符号整型,必须与influxdb版本兼容
# influx_uint_support = false
处理插件
- 数值类型转换
- 枚举类型
- 字符串转换
- topN
聚合插件
- 直方图
- 最大最小值
输入插件 (非常多)
示例 输入对象为文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# # Reload and gather from file[s] on telegraf's interval.
# [[inputs.file]]
# ## Files to parse each interval.
# ## These accept standard unix glob matching rules, but with the addition of
# ## ** as a "super asterisk". ie:
# ## /var/log/**.log -> recursively find all .log files in /var/log
# ## /var/log/*/*.log -> find all .log files with a parent dir in /var/log
# ## /var/log/apache.log -> only read the apache log file
# files = ["/var/log/apache/access.log"]
#
# ## The dataformat to be read from files
# ## Each data format has its own unique set of configuration options, read
# ## more about them here:
# ## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.md
# data_format = "influx"
服务器输入插件
示例 kafka
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
# # Read metrics from Kafka topic(s)
# [[inputs.kafka_consumer]]
# ## kafka servers
# brokers = ["localhost:9092"]
# ## topic(s) to consume
# topics = ["telegraf"]
#
# ## Optional Client id
# # client_id = "Telegraf"
#
# ## Set the minimal supported Kafka version. Setting this enables the use of new
# ## Kafka features and APIs. Of particular interest, lz4 compression
# ## requires at least version 0.10.0.0.
# ## ex: version = "1.1.0"
# # version = ""
#
# ## Optional TLS Config
# # tls_ca = "/etc/telegraf/ca.pem"
# # tls_cert = "/etc/telegraf/cert.pem"
# # tls_key = "/etc/telegraf/key.pem"
# ## Use TLS but skip chain & host verification
# # insecure_skip_verify = false
#
# ## Optional SASL Config
# # sasl_username = "kafka"
# # sasl_password = "secret"
#
# ## the name of the consumer group
# consumer_group = "telegraf_metrics_consumers"
# ## Offset (must be either "oldest" or "newest")
# offset = "oldest"
#
# ## Data format to consume.
# ## Each data format has its own unique set of configuration options, read
# ## more about them here:
# ## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.md
# data_format = "influx"
#
# ## Maximum length of a message to consume, in bytes (default 0/unlimited);
# ## larger messages are dropped
# max_message_len = 1000000
生成配置
telegraf config >telegraf_test.conf
启动
数据格式
输入格式
influxdb line protocol
collectd
csv
dropwizard
graphite
grok
json
logfmt
nagios
value
wavefront
输出格式
influxdb line protocol
json
graphite
splunkmetric
插件
输入 input
数据的输入格式约定
输出 output
数据的输出格式约定
处理 process
数据的清理
聚合 aggregator
数据的探索性统计
入门示例-机器性能采集
前提:influxdb已安装
概要:收集机器性能指标并存入到influxdb中
配置
输出插件选用influxdb
1
2
3
4
5
6
7
[[outputs.influxdb]]
urls = ["http://127.0.0.1:8086"]
database = "telegraf"
username = "telegraf"
password = "telegraf_88"
输入插件选用telegraf默认插件
cpu/disk/diskio/kernel/mem/processes/swap/system
启动
service telegraf start
参考 TICK技术栈