原理:通过telegraf将端上的log采集输出到influxdb,然后使用grafana进行数据可视化
场景1:监控web访问日志
采集设置
1
2
3
4
5
6
[agent]
interval = "1s"
flush_interval = "1s"
precision = "s"
hostname = "xxxx"
输出设置
1
2
3
4
5
6
7
8
[[outputs.influxdb]]
urls = ["http://xxx:8086"]
database = "xxx"
skip_database_creation = true
retention_policy = "autogen"
username = "xxxx"
password = "xxxx"
输入设置
1
2
3
4
5
6
7
8
9
10
11
12
[[inputs.logparser]]
files = ["/xxx/logs/access.log"]
from_beginning = false
watch_method = "inotify"
[inputs.logparser.grok]
patterns = ["%{COMBINED_LOG_FORMAT}"]
measurement = "web_log"
timezone = "Asia/Shanghai"
telegraf的logparser吸取了logstash的grok精髓
influxdb中的存储结构
tag
1
2
3
4
host 端主机名
path 端日志路径名
resp_code 响应码
verb 请求方法
field
1
2
3
4
5
6
7
8
agent string
auth string
client_ip string
http_version float
ident string
referrer string
request string
resp_bytes integer
场景2: 监控suricata统计信息
总的流程同上,但上面的例子使用现成的pattern,而本例使用自定义的pattern
采集设置
相同
输出设置
相同
输入设置
1
2
3
4
5
6
7
8
9
10
11
12
[[inputs.logparser]]
files = ["/xxx/suricata/log/stats.log"]
from_beginning = false
watch_method = "inotify"
[inputs.logparser.grok]
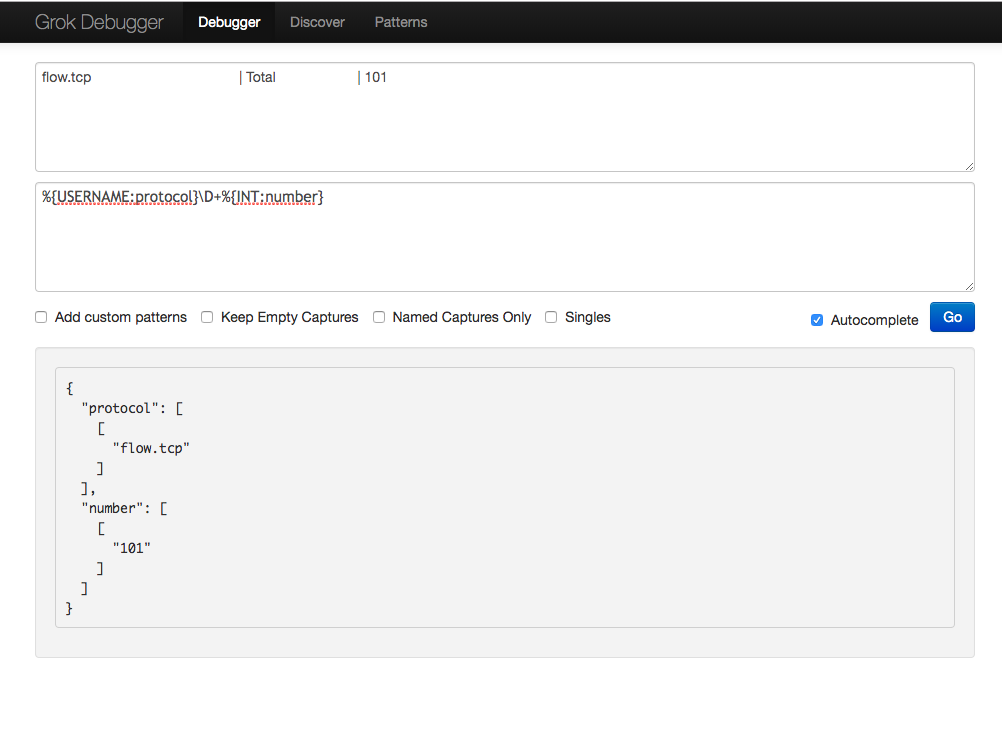
patterns = ['flow.%{WORD:protocol:tag}\D+%{INT:number:float}']
measurement = "suricata_stats_log"
timezone = "Asia/Shanghai"
influxdb中的存储结构
tag
1
2
3
host 端主机名
path 端日志路径名
protocol suricata统计项
field
1
number float
###
grok tips
telegraf的inputs.logparser采纳了logstash的grok语法
语法
%{<capture_syntax>[:<semantic_name>][:<modifier>]}
-
第一个字段: pattern,先查看已有的pattern是否能满足,否则采用自定义pattern(pattern就是正则大法)
-
第二个字段: 捕获的字段名
-
第三个字段:修饰符
telegraf常用的修饰符如下
| 类型 | |
|---|---|
| string | 默认类型 |
| int | |
| float | |
| duration | 可以将5.23ms转换为ns |
| tag | 该字段标记为tag类型 |
| drop | 不记录该字段 |
grok 速查表