基本概念
kapacitor属于TICK技术栈中的K,它定位为流式数据分析框架,包括数据源订阅,数据处理,预警检测与事件输出
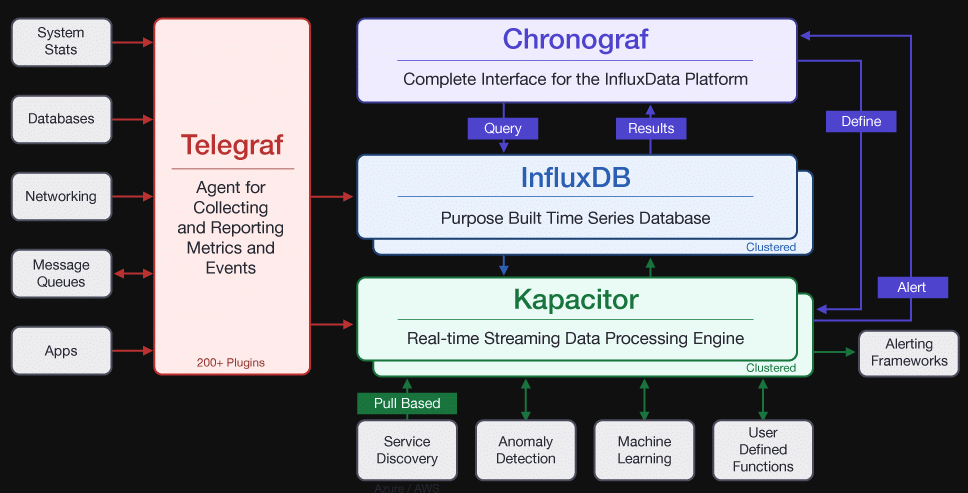
-
数据订阅源可以是influxdb,collectd,opentsdb等时序数据库
-
数据处理包括基于InfluxQL的批处理与将数据存储在内存中的流处理,并使用tick脚本来进行处理规则的定义
-
预警检测借鉴了nagios等成熟的监控方法,包括状态变更处理、抖动预警处理等
-
事件输出源可以是influxdb,email,http post,tcp, log, telegram,kafka,alerta,MQTT等
核心概念
| 名词 | 说明 | 同比influxdb |
|---|---|---|
| task | 数据计算规则,由一系列节点node形成的数据处理的有向无环图DAG | 无 |
| task template | 同上,通过模版变量来定制task | 无 |
| topic | 预警检测程序-如果没有显示在alert中用topic指定,会用程序的alert node来代替 | 无 |
| event | 触发的报警事件 | 无 |
| handler | 报警事件输出程序 | 无 |
| topic handler | 报警事件的输出有两种方式,一种是alert node的属性方法直接调用,一种是通过alert指定topic与yaml描述文件来定义 | 无 |
| record | 数据录制 | 无 |
| replay | 数据回放 | 无 |
| name | 度量名 | measurement |
| tags | 标签 | tag key tag field |
| columns | 字段 | field key |
| values | 字段值 | field value |
| series | 数据序列 | series |
| string template | 字符串模版,借鉴了go语言 | |
| lambda | 函数表达式 |
部署
安装
mac
brew install kapacitor
默认配置文件
/usr/local/etc/kapacitor.conf
centos
wget https://dl.influxdata.com/kapacitor/releases/kapacitor-1.5.1.x86_64.rpm
sudo yum localinstall kapacitor-1.5.1.x86_64.rpm
默认配置文件
/etc/kapacitor/kapacitor.conf
配置
环境变量设置
vim ~/.bashrc
export KAPACITOR_URL="http://localhost:9092
配置详解
数据文件配置
mkdir /home/work/kapacitor
chown -R kapacitor:kapacitor /home/work/kapacitor
vim /etc/kapacitor/kapacitor.conf
data_dir = "/home/work/kapacitor"
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
[replay]
# Where to store replay files, aka recordings.
dir = "/home/work/kapacitor/replay"
[task]
# Where to store the tasks database
# DEPRECATED: This option is not needed for new installations.
# It is only used to determine the location of the task.db file
# for migrating to the new `storage` service.
dir = "/home/work/kapacitor/tasks"
# How often to snapshot running task state.
snapshot-interval = "60s"
[storage]
# Where to store the Kapacitor boltdb database
boltdb = "/home/work/kapacitor/kapacitor.db"
日志配置
vim /etc/kapacitor/kapacitor.conf
1
2
3
4
5
6
7
8
[logging]
# Destination for logs
# Can be a path to a file or 'STDOUT', 'STDERR'.
file = "/home/work/kapacitor/log/kapacitor.log"
# Logging level can be one of:
# DEBUG, INFO, ERROR
# HTTP logging can be disabled in the [http] config section.
level = "INFO"
vim /etc/init.d/kapacitor
错误日志设置
1
2
3
if [ -z "$STDERR" ]; then
STDERR=/home/work/kapacitor/log/kapacitord.err
fi
vim /etc/logrotate.d/kapacitor
日志轮询设置
1
2
3
4
5
6
7
8
9
10
/home/work/kapacitor/log/kapacitor.log
/home/work/kapacitor/log/kapacitord.err
{
daily
rotate 7
missingok
dateext
copytruncate
compress
}
kapacitor主机配置
hostname = "localhost"
当kapacitor与influxdb不在同一台机器上时,需要配置influxdb可以通信的IP或主机名
时区配置
1
2
[Service]
Environment="TZ=Asia/Shanghai"
端口配置
1
2
3
4
5
6
7
[http]
# HTTP API Server for Kapacitor
# This server is always on,
# it serves both as a write endpoint
# and as the API endpoint for all other
# Kapacitor calls.
bind-address = ":9092"
注: 修改默认端口是好的安全习惯
influxdb配置
配置influxdb数据源,可以有多个通过name区分的influxdb源,并且需要将其中一个源设置为默认
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[[influxdb]]
enable = true
default = true
name = "data_source_1"
[[influxdb]]
enable = true
default = false
name = "data_source_2"
[influxdb.subscriptions]
# my_database = [ "default", "longterm" ]
[influxdb.excluded-subscriptions]
# my_database = [ "default", "longterm" ]
-
当task使用stream模式时,本质是kapacitor监听接口接收到了 influxdb line protocol格式的数据。可以通过配置subscriptions(当配置了subcription,influx数据源会生成一个指向kapacitor的订阅)或者直接发送该协议格式的数据给kapacitor监听接口;
-
当task使用batch模式时,kapacitor会使用数据源所在的influxdb进行查询操作,因此需配置执行查询的influxdb的地址与账号。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
[[influxdb]]
# Connect to an InfluxDB cluster
# Kapacitor can subscribe, query and write to this cluster.
# Using InfluxDB is not required and can be disabled.
enabled = true
default = true
name = "localhost"
urls = ["http://xxx.xxx.xxx.xxx:8086"]
username = "telegraf"
password = "telegraf"
timeout = 0
[influxdb.subscriptions]
# Set of databases and retention policies to subscribe to.
# If empty will subscribe to all, minus the list in
# influxdb.excluded-subscriptions
#
# Format
# db_name = <list of retention policies>
#
# Example:
# my_database = [ "default", "longterm" ]
telegraf=["four_week"]
查看当前订阅
kapacitor stats general
该配置会在influx数据源生成一个订阅
1
2
3
4
5
> show subscriptions
name: telegraf
retention_policy name mode destinations
---------------- ---- ---- ------------
four_week kapacitor-840a2fca-b0f5-4b6f-bfc8-0d1f0331c864 ANY [http://localhost:8192]
同时在kapacitor日志中可以看到
ts=2018-11-29T19:59:00.004+08:00 lvl=info msg="http request" service=http host=127.0.0.1 username=- start=2018-11-29T19:59:00.003082407+08:00 method=POST uri=/write?consistency=&db=telegraf&precision=ns&rp=four_week protocol=HTTP/1.1 status=204 referer=- user-agent=InfluxDBClient request-id=28515270-f3ce-11e8-8542-000000000000 duration=1.394643ms
邮件配置
kapacitor可以将alert预警事件流指向多个数据接收源,常用的有SMTP、HTTP接口等
1
2
3
4
5
6
7
8
9
10
11
12
13
[smtp]
# Configure an SMTP email server
# Will use TLS and authentication if possible
# Only necessary for sending emails from alerts.
enabled = true
host = ""
port = 25
username = ""
password = ""
# From address for outgoing mail
from = ""
# List of default To addresses.
to = ["oncall@example.com"]
UDF 自定义函数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
[udf]
# Configuration for UDFs (User Defined Functions)
[udf.functions]
# Example go UDF.
# First compile example:
# go build -o avg_udf ./udf/agent/examples/moving_avg.go
#
# Use in TICKscript like:
# stream.goavg()
# .field('value')
# .size(10)
# .as('m_average')
#
# uncomment to enable
#[udf.functions.goavg]
# prog = "./avg_udf"
# args = []
# timeout = "10s"
# Example python UDF.
# Use in TICKscript like:
# stream.pyavg()
# .field('value')
# .size(10)
# .as('m_average')
#
# uncomment to enable
#[udf.functions.pyavg]
# prog = "/usr/bin/python2"
# args = ["-u", "./udf/agent/examples/moving_avg.py"]
# timeout = "10s"
# [udf.functions.pyavg.env]
# PYTHONPATH = "./udf/agent/py"
# Example UDF over a socket
#[udf.functions.myCustomUDF]
# socket = "/path/to/socket"
# timeout = "10s"
启动
centos
service kapacitor start|stop|restart
kapacitor cli使用
通用选项
kapactiro -url http://host:port -skipVerify
服务管理
备份数据库
kapacitor backup [PATH_TO_BACKUP_FILE]
查看运行状态
kapacitor stats ingress
kapacitor stats general
查看变量
kapacitor vars | python -m json.tool
service-tests
枚举可用服务
kapacitor list service-tests
查看指定服务
1
2
3
4
5
kapacitor service-tests slack talk smtp
Service Success Message
slack false service is not enabled
talk false service is not enabled
smtp true
日志
查看日志
kapacitor logs [service=<SERVICE_ID>] [lvl=<LEVEL>]
日志级别:debug info error
e.x.
kapacitor logs service=http lvl=debug+
设置日志级别
kapacitor level error|debug|info
查看task执行情况
kapacitor watch <TASK_ID> [<TAGS> ...]
数据录制与回放
录制 record
record batch
kapacitor record batch (-no-wait) [-past <WINDOW_IN_PAST> | -start <START_TIME> -stop <STOP_TIME>] [-recording-id <ID>] -task <TASK_ID>
record stream
kapacitor record stream -duration <DURATION> (-no-wait) (-recording-id <ID> ) -task <TASK_ID>
record query
kapacitor record query [-cluster <INFLUXDB_CLUSTER_NAME>] [-no-wait] -query <QUERY> [-recording-id <RECORDING_ID>] -type <stream|batch>
回放 replay
replay
kapacitor replay [-no-wait] [-real-clock] [-rec-time] -recording <ID> [-replay-id <REPLAY_ID>] -task <TASK_ID>
replay-live query
kapacitor replay-live query [-cluster <CLUSTER_URL>] [-no-wait] -query <QUERY> [-real-clock] [-rec-time] [-replay-id <REPLAY_ID>] -task <TASK_ID>
replay-live batch
kapacitor replay-live batch [-no-wait] [ -past <TIME_WINDOW> | -start <START_TIME> -stop <STOP_TIME> ] [-real-clock] [-rec-time] [-replay-id <REPLAY_ID>] -task <TASK_ID>
枚举 list
kapacitor list recordings
kapacitor list replays
删除 delete
kapacitor delete recordings <recording-id|pattern>
kapacitor delete replays <relpay-id|pattern>
topic和topic handlers 管理
topic:alert预警程序
topic handlers: 预警程序描述文件yaml
创建topic handler define-topic-handler
kapacitor define-topic-handler <PATH_TO_HANDLER_SCRIPT>
枚举topic与topic handler list
kapacitor list topics
kapacitor list topic-handlers
查看topic与topic handler show
kapacitor show-topic [TOPIC_ID]
kapacitor show-topic-handler [TOPIC_ID] [HANDLER_ID]
删除topic与topic handler delete
kapacitor delete topics <Topic-ID | Pattern>
kapacitor delete topic-handlers
task 和 task templates 管理
创建或者更新任务 - define
直接创建任务
kapacitor define <TASK_ID> -tick <PATH_TO_TICKSCRIPT> -type <stream|batch> [-no-reload] -dbrp <DATABASE>.<RETENTION_POLICY>
从模版创建任务
`
kapacitor define
从模版描述文件创建任务
kapacitor define <TASK_ID> -file <PATH_TO_TEMPLATE_FILE> [-no-reload]
json描述文件
-
每次修改task都需要更新
-
更新enable状态的task,默认reload,如果不需要reload,请使用-no-reload
创建模版 - define-template
kapacitor define-template <TEMPLATE_ID> -tick <PATH_TO_TICKSCRIPT> -type <string|batch>
enable任务
kapacitor enable <TASK_ID>
diable任务
kapacitor disable <TASK_ID>
reload任务
kapacitor reload <TASK_ID>
枚举任务 - list
kapacitor list tasks
枚举模版 - list
kapacitor list templates
查看任务执行情况 - show
kapacitor show [-replay <REPLAY_ID>] <TASK_ID>
查看模版执行情况 - show-template
kapacitor show-template <TEMPLATE_ID>
删除任务 - delete tasks
kapacitor delete tasks <Task-IDs | Pattern>
删除模版 - delete templates
kapacitor delete templates <Tempalte-IDs | Pattern>
HTTP API
通用
| http method | 说明 |
|---|---|
| GET | 查看 |
| POST | 写入 |
| PATCH | 修改 |
| DELETE | 删除 |
数据写入
POST /kapacitor/v1/write
同influxdb http api
| 查询字符串 | 说明 |
|---|---|
| db | 数据库 |
| rp | 存储策略 |
e.x.
POST /kapacitor/v1/write?db=DB_NAME&rp=RP_NAME
cpu,host=example.com value=87.6
任务
创建或修改任务
POST /kapacitor/v1/tasks
定义任务用POST,修改用PATCH
| json参数 | 说明 |
|---|---|
| id | 任务id |
| template-id | 模版id |
| type | stream/batch |
| dbrps | 数据库存储策略 |
| script | 脚本内容 |
| status | enabled/disabled |
| vars | 变量 |
vars变量类型
| 类型 | 说明 | e.x. |
|---|---|---|
| bool | ture/false | |
| int | 42 | |
| float | 2.5 | |
| duration | 1s/1000000000 | |
| string | “a string” | |
| regex | go_regexp | |
| lambda | ||
| star | ”*” | |
| list | [{“type”: TYPE, “value”: VALUE}] |
| 响应码 | 说明 |
|---|---|
| 200 | ok |
| 404 | 任务不存在 |
查看任务
GET /kapacitor/v1/tasks
| 查询字符串 | 默认 | 说明 |
|---|---|---|
| pattern | ||
| fields | ||
| dot-view | attributes | labels/attributes |
| script-format | formatted | formatted/raw |
| offset | 0 | |
| limit | 100 |
| 响应码 | 说明 |
|---|---|
| 200 | ok |
GET /kapacitor/v1/tasks/TASK_ID
| 查询字符串 | 默认 | ||
|---|---|---|---|
| dot-view | attributes | attributes/labels | |
| script-format | formatted | formatted/raw | |
| replay-id |
返回字段说明
| 属性 | 说明 |
|---|---|
| created | 创建时间 |
| modified | 修改时间 |
| last_enabled | 最近enable时间 |
| executing | 是否执行中 |
| error | 错误 |
| stats | 统计 |
| dot | 任务DAG图 |
| 响应码 | 说明 |
|---|---|
| 200 | ok |
| 404 | 任务不存在 |
删除任务
DELETE /kapacitor/v1/tasks/TASK_ID
| 响应码 | 说明 |
|---|---|
| 204 | ok |
httpOut
GET /kapacitor/v1/tasks/TASK_ID/mycustom_endpoint
模版 template
创建或修改模版
POST /kapacitor/v1/templates
PATCH /kapacitor/v1/templates/TEMPLATE_ID
查看模版
GET /kapacitor/v1/templates
GET /kapacitor/v1/templates/TEMPLATE_ID
删除模版
DELETE /kapacitor/v1/templates/TEMPLATE_ID
录制 record
回放 replay
预警
关键字
- topic 预警检测程序-如果没有显示在alert中用topic指定,会用程序的alert node来代替
- event 触发的报警事件
- handler 报警事件输出程序
-
topic-handler 报警事件的输出有两种方式,一种是alert node的属性方法直接调用,一种是通过alert指定topic与yaml描述文件来定义 无
查看topics
GET /kapacitor/v1/alerts/topics
| 查询字符串 | 默认 | 说明 |
|---|---|---|
| min-level | OK | OK/INFO/WARNING/CRITICAL |
| pattern | * |
GET /kapacitor/v1/alerts/topics/<topic_id>
查看topic event
GET /kapacitor/v1/alerts/topics/<topic_id>/events
| 查询字符串 | 默认 | 说明 |
|---|---|---|
| min-level | OK | OK/INFO/WARNING/CRITICAL |
查看topic handlers
GET /kapacitor/v1/alerts/topics/<topic_id>/handlers
创建/修改topic handlers
POST /kapacitor/v1/alerts/topics/<topic_id>/handlers
删除topic
DELETE /kapacitor/v1/alerts/topics/system
删除topic handlers
DELETE /kapacitor/v1/alerts/topics/<topic_id>/handlers
配置
查看配置
GET /kapacitor/v1/config
存储
备份
curl http://localhost:9092/kapacitor/v1/storage/backup > kapacitor.db
日志
GET /kapacitor/v1preview/logs?task=mytask
testing services
GET /kapacitor/v1/service-tests
GET /kapacitor/v1/service-tests/<service name>
其他
ping
GET /kapacitor/v1/ping
var
GET /kapacitor/v1/debug/vars
pprof
GET /kapacitor/v1/debug/pprof/
api route /kapacitor/v1/:routes
GET /kapacitor/v1/:routes
TICK语法
TICK语言属于领域专业语言DSL,语法相对通用目的语言GPL简单很多。它将数据处理的流程描述为一个有向无环图(与spark的DAG类似),每一个数据处理节点为一个node,每个node都有其特定的功能,包括数据源定义节点、数据定义节点、数据操作节点、数据结构处理节点、数据变换节点、预警处理节点等
保留字
- TRUE
- FALSE
- AND
- OR
- lambda:
- var
- dbrp
操作符
普通操作符
- +
- -
- *
- /
- ==
- !=
- <
- <=
- >
- >=
- =~
- !~
- !
- AND
- OR
chain操作符
| 操作符 | 说明 | 示例 |
|---|---|---|
| | | chain方法调用 | | from() |
| . | 属性方法调用 | .database(mydb) |
| @ | UDF | @MyFunc() |
变量
类型标识符
可在任务模版变量中使用
| 标识符 | 说明 | |
|---|---|---|
| string | 字符串 | |
| duration | 时间 | |
| int | 整型 | |
| float | 浮点型 | |
| lambda | 匿名函数 |
e.x.
var measurement string
数据类型
boolean
- TRUE
- FALSE
string
- 使用单引号 ‘
- 三引号 ‘’’
- + 做字符串连接操作
- string templates
e.x.
.message(' is alivedead: points/10s.')
string lists
e.x.
` [ ‘host’, ‘cpu’ ] `
duration
- u or µ
- ms
- s
- m
- h
- d
- w
int
float
boolean
- TRUE
- FALSE
regex
e.x.
var cz_turbines = /^cz\d+/
` .where(lambda: “dns_node” =~ /.za$/ )`
lambda
e.x.
lambda: floor("usage_idle" * 1000.0)/1000.0
lambda中的计算式一定要类型相同,可以通过类型转换函数来统一
- bool()
- int()
- float()
- string()
- duration()
node (重点)
node类型
| 类型 | 小类型 | 示例 | 说明 | |
|---|---|---|---|---|
| 特殊节点 | alert | |||
| influxQL | ||||
| 数据源定义节点 | batch | |||
| stream | ||||
| 数据定义节点 | query | batch+query | ||
| from | stream+from | |||
| 数据操作节点 | window | stream+from+window 时间窗口 | ||
| where | stream+from+where 类型influxql where子句 | |||
| shfit | 时间窗口移动,用于同比,环比 | |||
| sample | ||||
| default | ||||
| 处理节点 | 数据结构改变 | groupBy | ||
| join | ||||
| union | ||||
| combine | ||||
| eval | ||||
| 处理节点 | 数据变换 | delete | ||
| derivative | ||||
| flatten | ||||
| stats | ||||
| stateCount | ||||
| stateDuration | ||||
| influxQL | ||||
| 处理节点 | 预警处理 | alert | ||
| deadman | ||||
| log | ||||
| httpOut | ||||
| influxDBOut | ||||
| httpPOST | ||||
| k8sAutoscale | ||||
| kapacitorLoopBack |
常用node
| node | 构造 | 属性方法 | chain方法 | 官方文档 | 说明 |
|---|---|---|---|---|---|
| batch | 无 | quiet | deadman,query,stats | batch | |
| stream | 无 | quiet | deadman,from,stats | stream | |
| query | query(“select .. from .. where ..”) | period,every,groupBy | query | ||
| from | from() | database,retentionPolicy,measurement,groupBy,where | window,sum | from | |
| window | window() | period,every,align | window | ||
| sum | sum(“field”) | as | influxQL | derivative有特殊的节点 | |
| shift | shift(duration) | shift | |||
| join | join(node) | as | join | ||
| alert | alert() | crit,log | alert | ||
| eval | eval(lambda) | keep,as | eval | ||
| influxDBOut | influxDBOut() | create,database,rententionPolicy,measurement,tag | influxDBOut | ||
| httpOut | httpOut(end_point) | httpOut | /kapacitor/v1/tasks/ |
||
| log | log() | log |
from 节点
- 多个where子句是AND的关系
- where子句的坑
1
2
3
4
5
6
7
var data = stream
|from()
.measurement('cpu')
var total = data
.where(lambda: "cpu" == 'cpu-total')
var others = data
.where(lambda: "cpu" != 'cpu-total')
等同于
1
2
3
4
5
6
var data = stream
|from()
.measurement('cpu')
.where(lambda: "cpu" == 'cpu-total' AND "cpu" != 'cpu-total')
var total = data
var others = total
query 节点
tick脚本中可用的influxql
1
2
3
SELECT {<FIELD_KEY> | <TAG_KEY> | <FUNCTION>([<FIELD_KEY>|<TAG_KEY])}
FROM <DATABASE>.<RETENTION_POLICY>.<MEASUREMENT>
WHERE {<CONDITIONAL_EXPRESSION>}
alert 节点
- alert事件数据的组成
| 字段 | 说明 |
|---|---|
| ID | |
| Message | |
| Details | HTML |
| Time | |
| Duration | 持续时间 |
| Level | |
| Data | |
| Recoverable |
- alert事件Message中可用的模版变量
| 模版字符串 | 内容 | |
|---|---|---|
| {{.ID}} | alert ID | |
| {{.Name}} | measurement | |
| {{.TaskName}} | task name | |
| {{.Group}} | [key=value,]+ | |
| {{.Tags}} | ||
| {{index .Tags “value”}} | 指定tag的值 | |
| {{.Level}} | alert 级别 INFO/WARNING/CRITICAL/OK | |
| {{.Fields}} | ||
| {{index .Fields “value” }} | 指定field的值 | |
| {{.Time}} | alert 时间 |
-
alert level类型 ok info warn critical
-
alert 处理报警的方式
noRecoveries() 不发送恢复报警
stateChangesOnly() level改变才发送报警
flapping(low float64, high float64) level频繁变更,但频率大于high时判定为flap状态,当频率小于low时离开flag状态
inhibit(category,tags) 按类型缩减报警
lambda(重点)
内置函数
| 参数 | 返回 | 说明 | 示例 | 类型 | |
|---|---|---|---|---|---|
| count | int64 | 次数 | count() | 状态函数 | |
| sigma | float64 | float64 | 3σ准则 | sigma(0.64) | 状态函数 |
| spread | float64 | float64 | 极值 | spread(0.64) | 状态函数 |
| int | int64 | 状态函数 | |||
| float | float64 | 状态函数 | |||
| string | string | 状态函数 | |||
| duration | duration ns | 状态函数 | |||
| isPresent | field/tag key | true/false | isPresent(“myfield”) | 存在函数 | |
| year | time | int64 | year(“time”) | 时间函数 | |
| month | time | [1,12] | month(“time”) | 时间函数 | |
| day | time | [1,31] | day(“time”) | 时间函数 | |
| weekday | time | [0,6] | weekday(“time”) | 时间函数 | |
| hour | time | [0,23] | hour(“time”) | 时间函数 | |
| minute | time | [0,59] | minute(“time”) | 时间函数 | |
| unixNano | time | int64 | unixNano(“time”) | 时间函数 | |
| max | time | float64 | max(x,xy) | 数学函数 | |
| min | time | float64 | min(x,xy) | 数学函数 | |
| regexReplace | regex,string,string | string | regexReplace(/a(b*)c/, ‘abbbc’,’group is $1’) | 字符串函数 | |
| humanBytes | string | 字符串函数 | |||
| if | string | if(“field” > threshold AND “field” != 0, ‘true’, ‘false’)) | 条件函数 |
TICK脚本编写注意事项
- lambda表达式tag或field的标识符用双引号,其他都用单引号
- query node中的influxql-query语句,只可以用select…from…where…
- lambda中的计算式一定要统一类型,(习惯脚本语言的特别容易犯这种错误)可以通过类型转换函数来统
- tick脚本一般由五部分组成:
- 变量定义 (可选)
- 数据源获取 batch…query 或者stream … from
- 数据变换处理 eval/shift/join等
- 预警处理 alert
- 预警输出 influxDBOut/httpOut
示例
错误率计算
| node | 构造方法 | 属性方法 |
|---|---|---|
| batch | ||
| query | query(‘SELECT sum(value) FROM “pages”.”autogen”.errors’) | period,every,groupBy,fill |
| join | join(views) | as |
| eval | eval(lambda: (“errors.sum” / (“views.sum” + “errors.sum”)) * 100) | as |
| influxDBOut | database,measurement |
| node | 构造方法 | 属性方法 |
|---|---|---|
| stream | ||
| from | from() | measurement,groupBy |
| window | window() | period,every |
| sum | sum(‘value’) | as |
| join | join(views) | as |
| eval | eval(lambda: “errors.sum” / (“views.sum” + “errors.sum”) * 100.0) | as |
| influxDBOut | database,measurement |
top 计算
| node | 构造方法 | 属性方法 |
|---|---|---|
| stream | ||
| from | from() | measurement,groupBy |
| window | window() | period,every,align |
| last | last(‘value’) | |
| groupBy | groupBy(‘game’) | |
| top | top(15, ‘last’, ‘player’) | |
| httpOut | httpOut(‘top_scores’) | |
| sample | sample(10s) | |
| influxDBOut | database,measurement | |
| max | max(‘top’) | |
| min | min(‘top’) | |
| join | join(min) | as |
| eval | eval(lambda: “max.max” - “min.min”, lambda: “max.max”, lambda: “min.min”) | |
| .as(‘gap’, ‘topFirst’, ‘topLast’) | ||
| influxDBOut | database,measurement |
创建模版任务
任务从文件夹自动加载
load 配置
1
2
3
4
5
6
[load]
# Enable/Disable the service for loading tasks/templates/handlers
# from a directory
enabled = true
# Directory where task/template/handler files are set
dir = "/etc/kapacitor/load"
load文件包括以下三个子目录
templates 子目录
存放模版tick脚本
tick脚本三要素
- id: 脚本名(不包括.tick)
- type: stream或者batch
- dbrp: 数据库与存储策略
e.x. implicit_template.tick
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
dbrp "telegaf"."not_autogen"
var measurement string
var where_filter = lambda: TRUE
var groups = [*]
var field string
var warn lambda
var crit lambda
var window = 5m
var slack_channel = '#alerts'
stream
|from()
.measurement(measurement)
.where(where_filter)
.groupBy(groups)
|window()
.period(window)
.every(window)
|mean(field)
|alert()
.warn(warn)
.crit(crit)
.slack()
.channel(slack_channel)
tasks 子目录
存放模版定义yaml/json文件和其他tick文件
模版定义四要素
- id 脚本名(不包括.yaml .yml .json)
- template-id: 模版名
- vars: 模版变量
- dbrp: 数据库与存储策略,如果模版tick文件未指明需填写
e.x.
implicit.yaml
1
2
3
4
5
6
7
8
9
10
11
12
template-id: implicit_template
vars: {
"measurement": {"type" : "string", "value" : "cpu" },
"where_filter": {"type": "lambda", "value": "\"cpu\" == 'cpu-total'"},
"groups": {"type": "list", "value": [{"type":"string", "value":"host"},{"type":"string", "value":"dc"}]},
"field": {"type" : "string", "value" : "usage_idle" },
"warn": {"type" : "lambda", "value" : "\"mean\" < 30.0" },
"crit": {"type" : "lambda", "value" : "\"mean\" < 10.0" },
"window": {"type" : "duration", "value" : "1m" },
"slack_channel": {"type" : "string", "value" : "#alerts_testing" }
}
handlers 子目录
topic handlers定义yaml/json文件
e.x.
1
2
3
4
5
6
topic: cpu
id: other
kind: slack
match: changed() == TRUE
options:
channel: '#alerts'
异常检测-UDF
Socket UDF
自定义handler
自定义output node
CQ v.s. Kapacitor stream v.s. batch
| work | 特点 |
|---|---|
| CQ | 不能执行复杂的数据计算 |
| stream | 消耗内存,窗口不能过大 |
| batch | 消耗influxdb资源 |
更多tick例子
chronograf 可视化
可以把chronograf当成tick编辑器
chronograf 编写报警规则
点击 Build Alert Rule
- 第一步:填写tcik脚本名
- 第二步:选择报警类型:threshold/relative/deadman
- 第三步:选择时序数据
- threshold:选择db,retention policy,measurement,tags,fields,group by,函数
- relative: 同上
- deadman: 选择db,retention policy,measurement,tags
- 第四步:报警条件设置
- threshold:区间设置
- relative: 变化/变化率设置 + 同比环比时间 + >=/<=/=/>/<
- deadman: 数据缺失时间段
- 第五步:选择alert handler (topic handler) log/email/等
- 第六步:使用templates字符串填写报警message
chronograf 编写tick脚本
点击 Write TICKscript
- 第一步:选择处理模型 stream或者batch
- 第二步:选择数据源
- 第三步:编写tick脚本
其他
时区设置问题
在报警邮件中使用当前时区
第一步:修改kapacitor配置文件
[Service]
Environment="TZ=Asia/Shanghai"
第二步:使用模版向量
\{\{ .Time.Local.Format "Mon, Jan 2 2006 at 15:04:05 MST"}}
需去掉转义字符
tick调试
-
使用httpOut节点输出数据
-
查看/kapacitor/v1/tasks/,跟踪node-states
数据恢复
kapacitor如果加载了会导致系统崩溃的tick脚本,那么kapacitor将会无法重启直到修正了该脚本
e.x.
panic: runtime error: integer divide by zero
kapacitor将task、alert存放在kapacitor.db中,该db为go语言编写的嵌入式的k/v数据库boltdb
我们可以从该数据库中恢复数据,当然最好是能备份每个tick脚本,因为发现kapacitor在重启的时候会出现丢失tick的情况
bug记录
-
同时间触发的alert事件,只有一个事件会输出
-
stats节点统计不准确
总结
kapacitor还在进化中,坑不少,但站在众多数据处理框架肩膀上的设计思路还是很有借鉴性的